

When it comes to large language models, there seems to be a lot of confusion surrounding what they actually are, how they work, and how they will affect the future.
These are the questions we will address today.
The Imitation Game
Let’s begin with the Turing test, which was proposed by Alan Turing in 1950.
It’s a benchmark in artificial intelligence used to assess a machine's ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human.
The test involves a human judge interacting with both a machine and a human through text-based communication without visual cues.
Basically, a chat interface.
If the judge cannot reliably distinguish between the responses of the machine, and the human, the machine is considered to have passed the Turing test.
If one interacts with an LLM today, especially one designed to be conversational, like Inflections Pi or an avatar on Character AI, then I think it's clear we’ve blown past the original Turing test.
But LLMs still have a long way to go. They don’t have long term memory and can’t perform simple math functions. Perhaps most importantly, they don’t form mental models of what the world is actually like.
And according to Yann LeCun, Chief AI Scientist at Meta, large language models might not even be the right architecture for achieving these goals.

So how do LLMs work and where can they go from here?
How Did We Get here in 2 Minutes or Less
One could reliably trace the origins of artificial intelligence back to people like Alan Turing or Vannevar Bush.
But for the purposes of this conversation, we have to start in 2015, when Ilya Sutskever (former OpenAI co-founder and Chief Scientist at OpenAI) and others published a paper called Reinforcement Learning Neural Turing Machines.
This approach combined the principles of neural networks with the computational capabilities of Turing machines (computers), particularly focusing on reinforcement learning.

By incorporating reinforcement learning techniques, an LLM model proved it could efficiently handle a vast number of sequential computational steps, showcasing its power and versatility in solving complex problems. The key word here is sequential.
Then in 2017, Ashish Vaswani (founder Essential AI) and Noam Shazeer (founder of Character AI) among others, published a paper called “Attention is All You Need” which introduced the transformer architecture.
We propose a new, simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality, while being more parallelizable and requiring significantly less time to train.
The key word here is parallelizable, which allows models to perform their computations simultaneously, rather than sequentially. This need for computations to be done in parallel, is the reason GPU’s are used in training, rather than CPU’s.
Which brings us to the LLMs that have exploded onto the scene today.
Generative Pretrained Transformers (GPT)
Transformer architecture is what underlies almost all of the new “artificial intelligence” consumer products today.
They are generative, meaning they do not simply retrieve stored information, but rather, generate new information based on data they have been trained on.
They are pretrained, meaning they have been trained using reinforcement learning on huge corpuses of data.
And they utilize transformer architecture, meaning it allows the model to weigh the significance of different words relative to each other, which allows it to predict what comes next.
How it Works
The self-attention mechanism generates three vectors for each word:
Query (Q), Key (K), and Value (V) vectors through linear transformations of the input.
Attention scores are calculated by taking the dot product of the Query vector with Key vectors of all positions, followed by a softmax operation to normalize the scores. The output is a weighted sum of the Value vectors, where the weights are the attention scores.
This above quote sounds like the adults talking in a Charlie Brown cartoon to me. So let’s break it down.
Did you ever have to diagram a sentence in language arts class? That’s basically what a transformer does.

Take the following sentence:
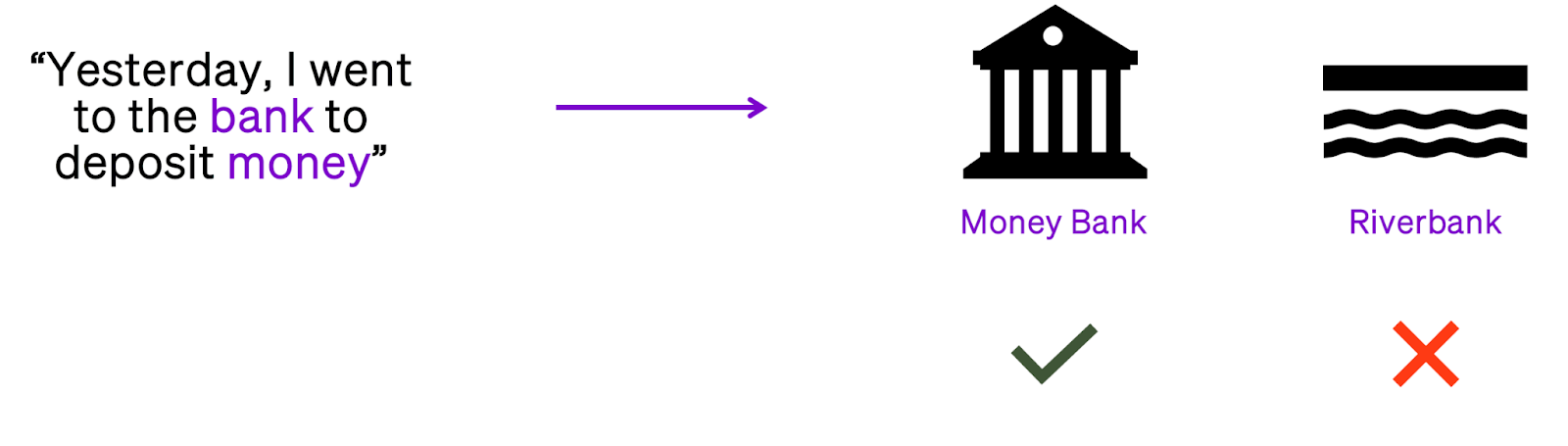
“Yesterday, I went to the bank to deposit money.”
The word “money” allows the model to understand that the sentence refers to a money bank, not a river bank.
It takes a string of words and represents them as sequences of numbers called vectors.
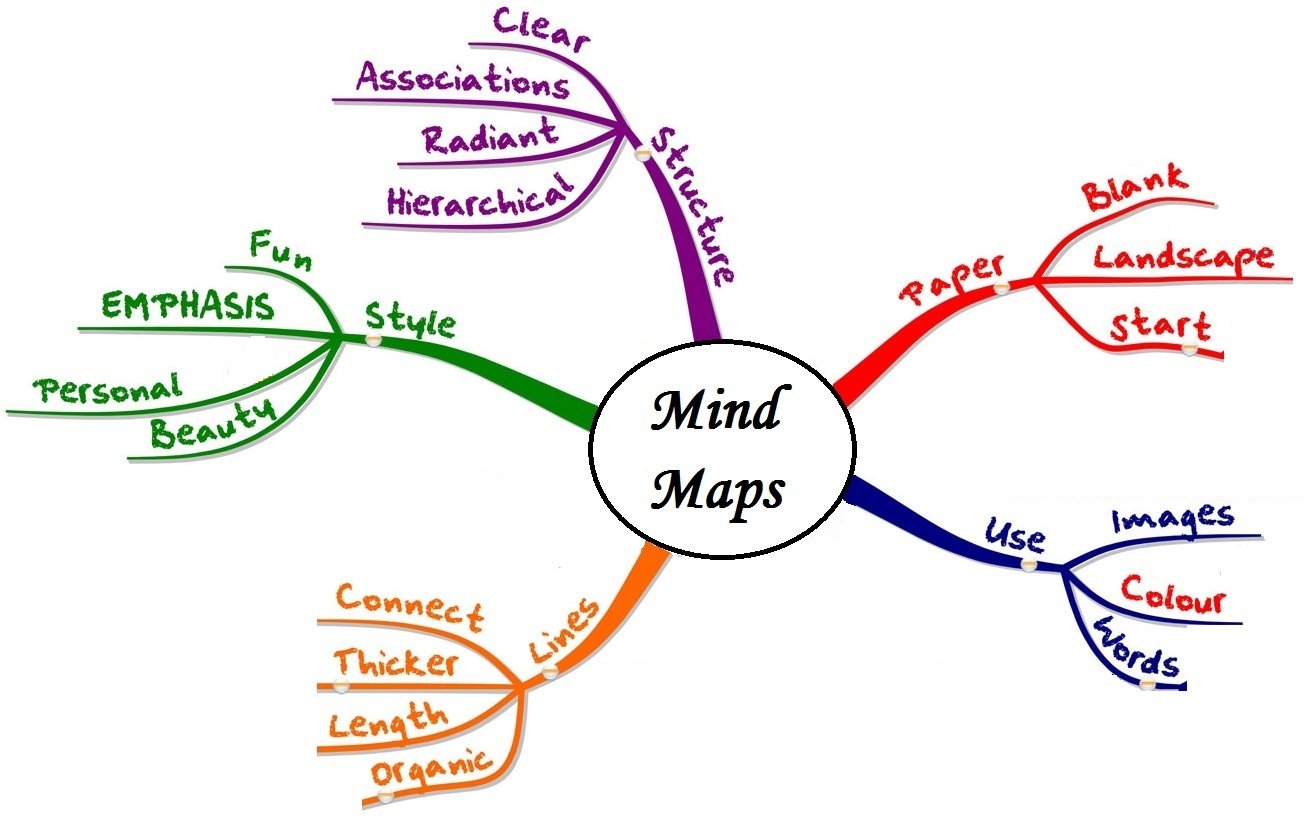
Each number within the vector captures the meaning of a word in relation to other words. Think of this like a mind map. When two words are closely related, they’re mapped closely together. Using these vectors, it assigns a probability to each word so it can guess what word should logically come next.
{kind=link}

Training
Large language models are built in two key stages:
The training stage, which feeds the model terabytes of data so that it can learn what different words mean, and how closely they are related, with the goal of eventually generating text by predicting the next word.
The fine-tuning stage, which trains the foundational model to perform a particular kind of task like answering questions or being a helpful customer service agent.
Initially, the connections between nodes will be assembled randomly, so the model’s prediction will also be random.

But as the model is trained, the nodes learn to predict the output that we want to see by adjusting the weights and biases that connect them together.

The number of weights and biases that a model uses to make a prediction are called “parameters”. The more parameters there are, the more complex the model.
While this often leads to better performance, it also comes at the cost of higher latency and computational demand.
Newer language models aim to outperform larger models by using fewer parameters but improving on the architecture and leveraging higher quality training data.
Indeed, one of the new races in AI is to build a small language model that is fast, accurate, and could be integrated directly into the OS of a smartphone. Apple has hinted this is their primary focus in 2024. Hopefully it can save their stock price.
Once the model can predict answers in the desired format, human feedback is used to rank several of the model’s possible responses from best to worst in a process called “reinforcement learning from human feedback” (RLHF). This feedback is used to train a second “reward model” which further helps fine tune the LLM to output the best response.

This RLHF feedback mechanism is the reason why so many people were aghast in regard to the inaccurate and blatantly racist Gemini model shipped by Google. An essential part of the training process is “reinforcement learning from human feedback”.
Dream Machines

The term 'hallucinations' often surfaces in discussions about LLMs, typically highlighting their unpredictability and potential risks in business applications.
Yet Andrej Karpathy, former OpenAI co-founder and developer, provides a refreshing counterpoint to this narrative.
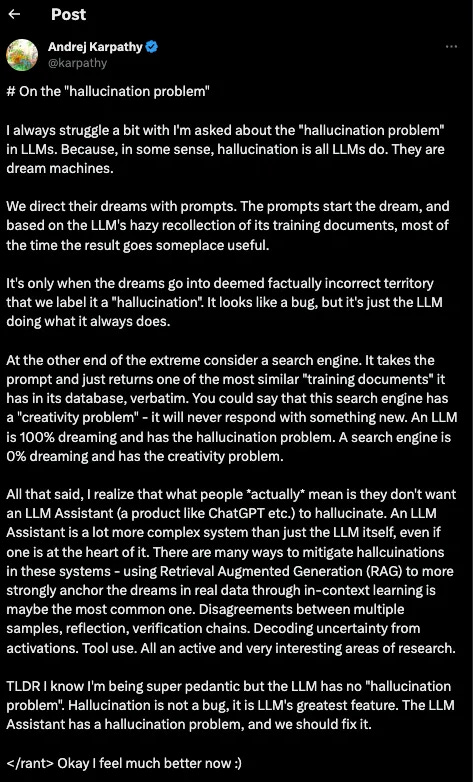
Karpathy describes LLMs as "dream machines," arguing that what we perceive as hallucinations are a feature, not a bug. In fact, the LLM is dreaming 100% of the time.
This is the pivotal point when we consider current LLM architecture. In consumer apps, most people are willing to forgive the occasional hallucination as long as they are getting value, on average, from the output.

What’s Next?
has a cogent point in his Clouded Judgment newsletter: Unfortunately two competing statements can be true:
AI is a major platform / tech shift and will change the world
AI is in a bubble
There are three main reasons for this:
We’re waiting for highly accurate AI agents (though Devin get’s close)
We’re waiting for AI products to have effective memory.
The 90/10 problem (accurate 90% of the time, wrong 10%)
If a surgeon or physicians assistant is using an AI enabled transcription tool, it must be 100% accurate. If it records AB negative blood type when the person is actually A negative, that’s a huge malpractice suit waiting to happen.
If you’re booking a plane ticket using an AI enabled agent, and it books the wrong time, airline, or location, you will never use that product again, even if it improves.
And
recently described on the podcast how Shopify’s customer service chatbots provided solutions to customer problems which didn’t exist, leading to a terrible customer experience.AI is no longer a blue ocean, its a blood bath
Blue Ocean strategy is about creating and capturing uncontested market space, thereby making the competition irrelevant.
-Peter Thiel
OpenAI capitalized on this when they released ChatGPT, and is still the leader across the industry so far. But it’s still anyone’s game.
The current state of play:
Google crashed and burned with their Gemini launch
Elon Musk sued OpenAI, and plans to open source the Grok code
OpenAI plans to release their incredible Sora model later this year
The space is not only crowded now, its about to get messy.
What’s more, the jury is still out on enterprise AI. Fortune 500 CIO’s will be hyperaware of the danger of uploading sensitive customer and internal data into these propriety models.
Therefore, ChatGPT, Claude, and Gemini may continue to serve the consumer and startup ecosystem as “off the shelf” solutions, whereas the enterprise market will be serviced by free, open source models like Llama and Mistral, which can be downloaded, fine tuned, and run locally on a company’s own data sets.
All of this makes many insiders like Bill Gurley, Brad Gerstner, and Alex Kolicich believe the newly minted AI industry will soon enter a trough of sorrow.
And as discussed above, Yann LeCun is not convinced that we can solve the accuracy and memory problems using LLM architecture at all. I invite you to listen to his interview on the Lex Fridman show linked below if you’d like to go deeper on this point.
We’re still in the very early days of this technology, and it will be exciting to follow it from here.

Unfortunately, two competing statements can be true:
AI is a major platform / tech shift and will change the world
AI is in a bubble
Thanks for sharing! Great read with a lot of useful information!
Its a short course on its own)