
Reasoning Revolution
Why 2026 Makes Superhuman Reasoning Cheap, Abundant, and Profitable

The year 2025 ended with large language models firmly in the reasoning era, burgeoning on the agentic era. What began with proprietary systems showing incremental gains in chain-of-thought capabilities, exploded into a broad, reproducible advances when open-weight models achieved parity at dramatically lower costs.
As we enter 2026, the current state of the landscape has shifted in ways that are only now becoming clear. More actors can reach the frontier, post-training bottlenecks have eased for high-value domains, and the pace of iteration is accelerating.
Don’t Miss the Bonus for Paid Subscribers
5 public company winners for 2026 based on the insights (cheaper frontier training + reasoning proliferation driving higher global compute volume and inference scale)
AND
Three sleeper/contrarian picks (higher-risk, less-consensus bets that could outperform if the abundance thesis plays out even more aggressively than expected)
At the end of the article.
The Cost Structure That Rewrote Assumptions
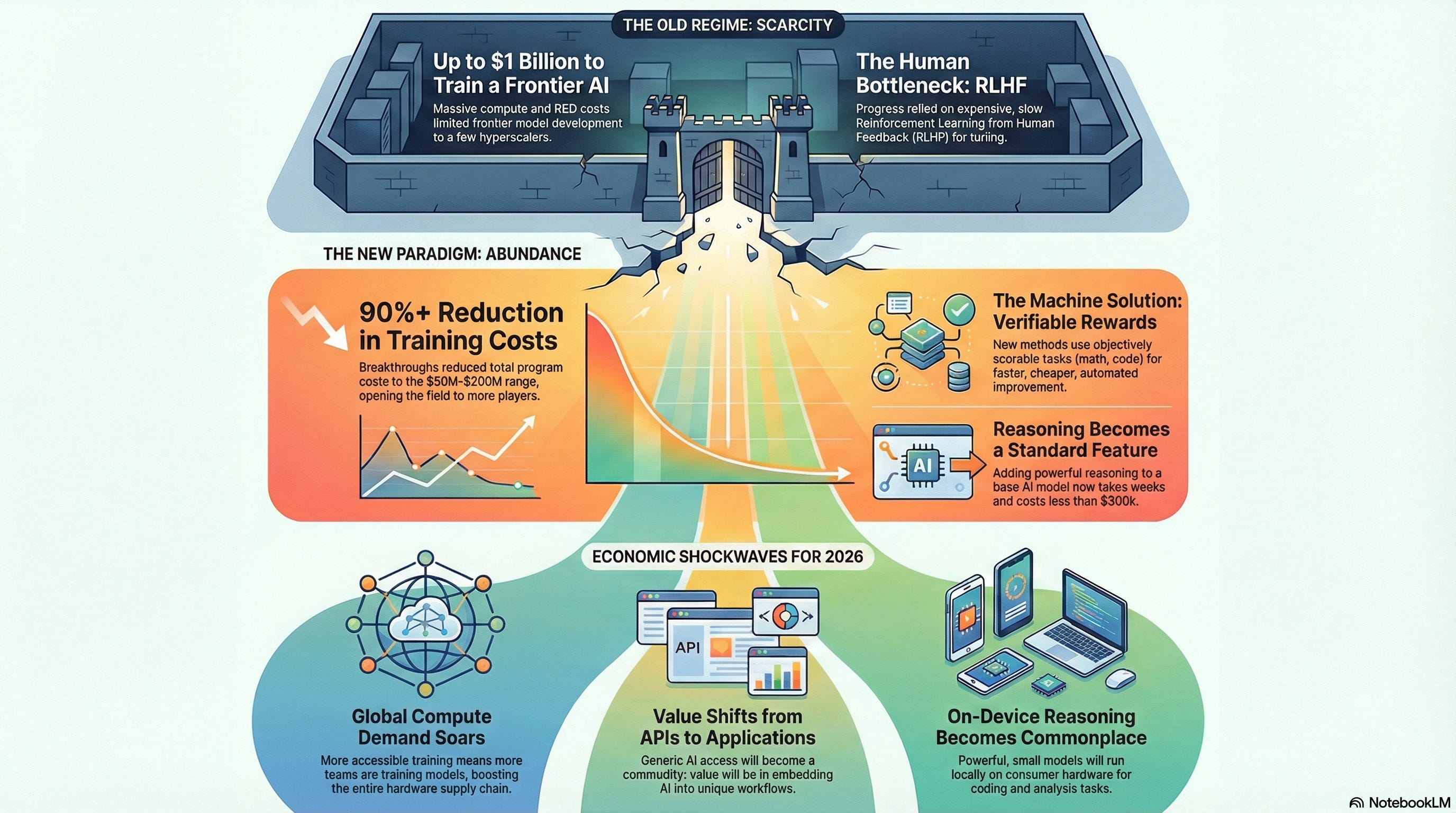
For years, conventional wisdom held that training a frontier model required compute budgets in the high hundreds of millions, often approaching a billion dollars when accounting for iteration and infrastructure.
DeepSeek’s late-2024 release of their 671 billion parameter V3 base model challenged that directly. Their reported final pre-training run consumed roughly 2.8 million GPU hours on H800 clusters, translating to approximately $5.6 million in rental compute credits at prevailing rates.
This figure, while precise for the successful run, naturally invites scrutiny. It excludes prior experimental runs, which likely consumed several times that amount in failed or partial trainings, hyperparameter searches, and architectural ablations.
It also omits personnel costs, data pipeline development, and the amortized expense of owning or leasing the underlying hardware cluster. Independent analyses in early 2025 placed total program costs, including these factors, somewhere between $50 million and $200 million, depending on assumptions about utilization efficiency and iteration depth.
Even at the higher end, the shift is profound. The industry moved from a regime where only a handful of hyperscalers could contemplate frontier training, to one where determined organizations, sovereign funds, or well-capitalized startups can mount credible efforts.
The final-run efficiency demonstrated that hardware utilization, mixture-of-experts architectures, and optimized data mixtures can compress compute requirements far below earlier scaling law extrapolations.
The Rewards Unlock (Post Training)
The more transformative innovation came in January 2025 with DeepSeek-R1.
Building directly on the V3 base, the team applied a reinforcement learning approach that relied on programmatically verifiable rewards, rather than human preference labels.
Termed RLVR, and implemented via the Group Relative Policy Optimization (GRPO) algorithm, this method targeted domains where outcomes are objectively scorable: mathematics competitions, code generation with unit tests, logical puzzles, and scientific question-answering datasets.
Traditional RLHF (Reinforcement Learning from Human Feedback) requires vast quantities of ranked responses, either expensively annotated by humans or synthetically generated in a precarious bootstrapping process.
Verifiable rewards eliminate the need for a separate reward model entirely. The training signal comes directly from the task environment. A correct final answer yields positive reinforcement, regardless of the path taken.
Models quickly learn that producing explicit, lengthy chains of thought correlates strongly with verifiable success. Therefore they are rewarded for this behavior and, like a pavlovian dog, this leads to the emergent reasoning behavior we now associate with these systems.
The reported additional compute for converting V3 into the initial R1 release was under $300,000, again reflecting only the final reinforcement phase.
Subsequent open-source replications and independent analyses confirmed that the core technique transfers across base models with similar efficiency.
By mid-2025, multiple laboratories had produced reasoning-capable variants of Llama, Qwen, and Mistral architectures using variants of GRPO, often in weeks rather than months.
Late-2025 Iterations That Raised the Bar
The trajectory accelerated through the year. DeepSeek itself released incremental versions, culminating in R1-0528 by late 2025, which deepened reasoning traces and improved tool integration.
More importantly, the team open-sourced distillation pipelines that transferred reasoning capability into dense models as small as 8 billion parameters.
Several of these distilled variants surpassed proprietary lightweight systems on mathematics and coding benchmarks, achieving state-of-the-art results among open dense models.
Hybrid approaches emerged, combining verifiable-reward reinforcement with limited supervised cold-start data to reduce artifacts like repetition or language mixing. By December 2025, reasoning capability had become a standard post-training stage for most serious open-weight releases, rather than a proprietary differentiator.
Model Release Cadence in 2026
Expect 2026 to feature a sharp increase in frontier-capable releases, both open and closed. The lowered post-training barrier means that any competent team with a strong base model can add competitive reasoning in a matter of weeks and modest compute.
We will likely see quarterly or even more frequent updates from leading open efforts, each incorporating longer context, better tool use, and refined verification mechanisms.
Proprietary laboratories will respond in kind, but their advantage in raw scale may narrow for reasoning-specific tasks. Domains like software engineering, quantitative finance, and automated research will see particularly rapid gains, as these align precisely with verifiable-reward training.
Smaller, specialized models trained end-to-end on proprietary datasets in these verticals could achieve superhuman performance on narrow, but economically viable workflows.
Distillation will proliferate further. The open availability of high-quality reasoning traces from frontier systems enables efficient transfer to models in the 7-70 billion parameter range, suitable for on-device or low-latency deployment.
By mid-2026, reasoning-enhanced models running locally on consumer hardware should become commonplace for coding assistance and analytical tasks.
Shifting Economics
Lower training thresholds do not reduce overall compute demand. In fact, the corollary is true. More training runs globally mean higher aggregate GPU consumption, benefiting the semiconductor supply chain.
Companies controlling fabrication capacity, chip design, and cluster efficiency retain strong positioning as the total volume of purchased compute expands.
At the application layer, general-purpose inference faces commoditization. When multiple open-weight systems offer comparable reasoning at similar latency, pricing power shifts toward distribution, user experience, and proprietary data integration.
Pure API providers serving undifferentiated frontier access will experience margin pressure. The highest returns will accrue to platforms that embed reasoning agents into defensible workflows. Think enterprise software suites, vertical research tools, automated trading systems, and developer environments where proprietary context provides lasting advantage.
Steelmanning the Case for Persistent Moats
A reasonable counterargument holds that the cost reductions are overstated and temporary. Replication from scratch still demands world-class talent, access to massive clean datasets that are increasingly scarce and expensive to curate, and months of iterative experimentation that can easily consume hundreds of millions in aggregate compute.
Moreover, verifiable rewards excel in structured domains, but struggle with open-ended, subjective tasks where proprietary preference data remains essential.
In this view, the frontier stays defended by cumulative R&D investment, data exclusivity, and the operational complexity of running massive clusters at high utilization. Open efforts may achieve periodic parity on benchmarks, but lag in real-world robustness and breadth.
This perspective carries weight, particularly for consumer-facing conversational agents where nuance and cultural fluency matter. Yet it underestimates the compounding effect of open iteration speed and the economic relevance of the domains where verifiable methods dominate.
The Misguided Appeal of Precautionary Slowdown
Calls to pause or heavily regulate frontier development often rest on the assumption that additional time guarantees better alignment outcomes. Experience suggests otherwise.
Unilateral restraint simply displaces progress to less constrained jurisdictions, while forgoing near-term productivity gains in software development, scientific discovery, and quantitative analysis.
The verifiable-reward paradigm itself reduces certain risks by incentivizing transparent reasoning traces that are easier to audit and intervene on, than opaque single-pass outputs.
Delaying proliferation would mean sacrificing measurable economic and intellectual advances for speculative safety improvements that may never materialize proportionally.
Below the paywall you will find:
5 public company winners for 2026 based on the insights (cheaper frontier training + reasoning proliferation driving higher global compute volume and inference scale)
AND
Two sleeper/contrarian picks (higher-risk, less-consensus bets that could outperform if the abundance thesis plays out even more aggressively than expected)
Keep reading with a 7-day free trial
Subscribe to Agora to keep reading this post and get 7 days of free access to the full post archives.