
Small Language Models
The New Edge Paradigm

It really does turn out that its not about the size of the ship, its about the motion of the ocean. And that’s not just cope.
For the last three years, the AI narrative has been driven by parameter counts, training runs that burn through hundreds of millions in compute, and centralized models that are so large they are now impractical for most use cases.
The good news is, the fast take off narrative, the endless self-recursive narrative, the AI doomsday narratives, all turned out to be speculative rubbish.
Rather than having one god model run everything, Small Language Models (SLMs) have emerged, not as the inferior cousin of LLMs, but as the operational backbone of localized AI.

SLMs, typically under ten billion parameters, now match eighty to ninety percent of LLM performance across targeted tasks. More importantly, they do so in environments where latency, privacy, and energy consumption dominate the economics.
This is the best of all possible worlds, where LLMs continue to push the frontier, but verticalized applications will begin to be built on these tightly coupled SLMs.
It’s also likely a new architecture will emerge as the step function changes from LLMs become less parabolic and more gradual.
The Device Stack
What’s happening
Small language models are shrinking to sizes between a few hundred megabytes and a few gigabytes, making them viable on phones, wearables, and smart glasses.
They already handle tasks like translation, summarization, coding help, and multimodal vision-language applications directly on consumer devices. Hardware makers are integrating them tightly, from Qualcomm’s AR chips to Alibaba’s AI glasses, enabling real-time processing without cloud reliance.
So what
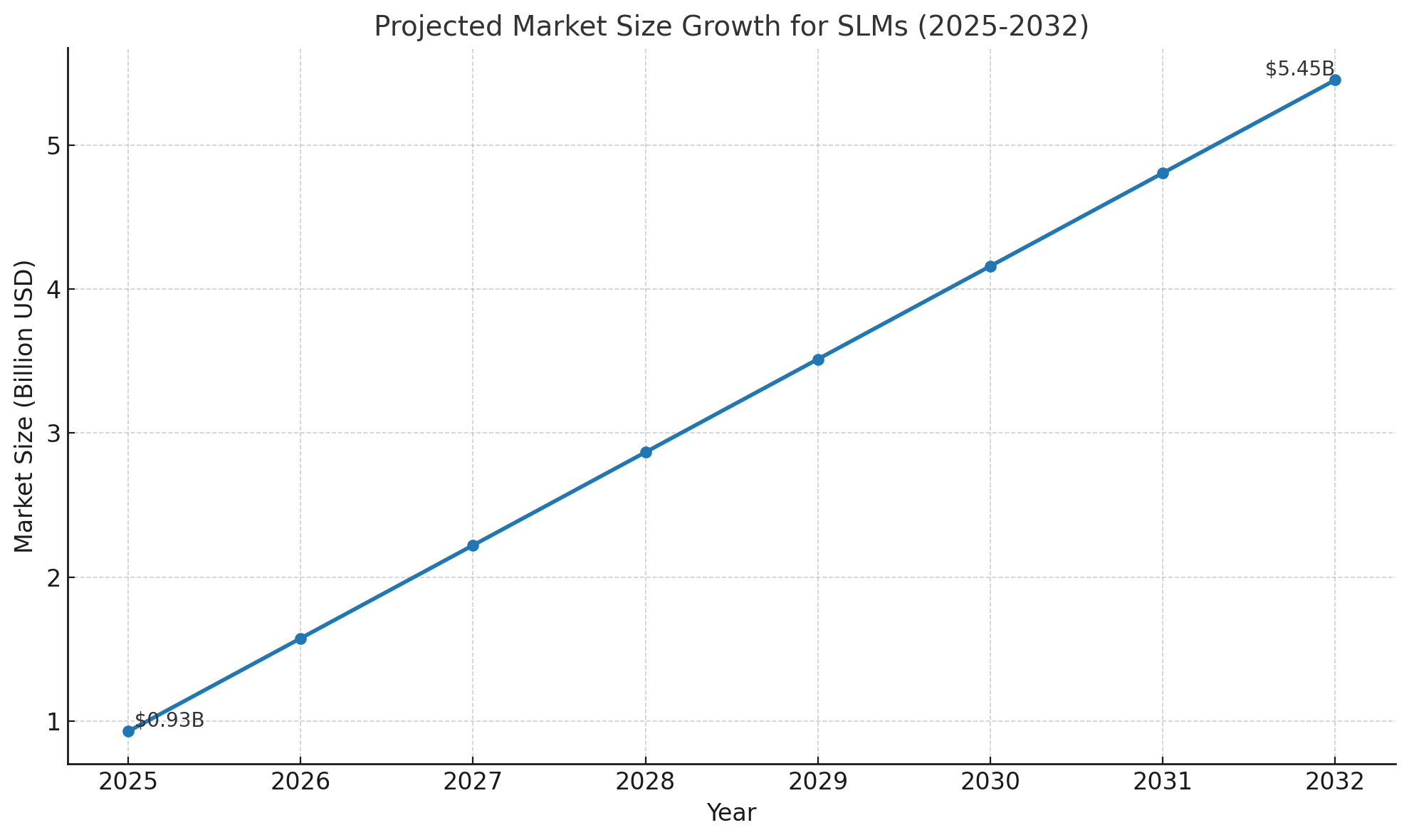
This shift turns everyday devices into powerful AI endpoints, cutting latency and boosting privacy while reducing dependence on large cloud models. It broadens access by bringing reasoning and multimodal AI to mid-tier consumer hardware, not just premium systems. With the SLM market set to expand nearly sixfold by 2032, efficiency and edge integration will become a central axis of competition and innovation.
The Buzz Word of 2025
What’s happening
SLMs are evolving from reactive tools into agentic systems that plan, reason, and act autonomously. NVIDIA’s 2025 benchmarks show they deliver up to ten times lower latency and far less power consumption than LLMs at the edge. Models like xLAM-2-8B, Nemotron-H, and SmolLM3 prove that sub-5B parameter agents can handle structured reasoning, dual-mode thinking, and 128k context windows while matching or surpassing larger models on cost and speed.
So what
Agentic SLMs are crossing into daily life, from wearables that adjust fitness plans to glasses that interpret environments and tutors that deliver 80 percent of LLM learning outcomes at 20 percent of the cost. The strategic play isn’t to rival frontier models like GPT-5, but to hit “good enough” autonomy where latency and efficiency matter most. This creates a consumer market where the winning AI is not the smartest, but the fastest, cheapest, and most embedded in everyday devices.

The Compute Layer
What’s happening
Qualcomm’s Snapdragon AR1 Plus is already running live Llama 3.2 workloads on AR glasses with 45 TOPS performance. NVIDIA’s Jetson series shows SLMs cutting wearable power draw by 90 percent compared to LLMs, while Apple’s Neural Engine sustains Phi-3.5 for health analytics on watches. These gains come from precision tricks like four-bit quantization and sparsity that make low-power, low-thermal inference viable.
So what
The frontier is no longer just model design but hardware co-design, where domain-specific accelerators unlock five to ten times cost reductions per inference. This shifts competitive advantage toward ecosystems that marry efficient SLMs with chips built for their quirks. For businesses, winning means getting closer to silicon, not just scaling parameters.

Small but Specialized
What’s happening
SLM architectures are maturing, with models like Mistral Small 3, Qwen 2 at 0.5B, and Tiny-R1-32B using distillation and synthetic data to achieve strong performance at small scales. SmolVLM at just 256M parameters is already handling browser-based multimodal tasks competently. The shift emphasizes specialization over universality, with models tailored to narrow domains and efficient enough to run entirely on consumer hardware.
So what
This approach makes data efficiency, not brute training scale, the real lever of progress. Proprietary fine-tuning enables healthcare, lightweight vision-language agents, and other verticals to unlock value with smaller models. The competitive edge will belong to those who can squeeze the most reasoning from the least data and deploy it everywhere.

Modularity and Privacy
What’s happening
The application layer makes the advantage of SLMs tangible. Google’s Gemini is already structured to run in a tiered fashion, with smaller versions handling on-device personalization and larger variants escalating in the cloud for harder tasks.
Wearables integrate SLM-powered coaching agents, and glasses provide live translation and productivity functions without constant uplink. Federated learning strengthens this design by enabling local training with aggregated updates, improving models without leaking private data.
So what
This modular edge-first approach turns privacy into a moat and efficiency into consumer loyalty. Firms that let SLMs absorb 70 to 80 percent of queries while escalating only when necessary see 20 to 30 percent improvements in retention.
The implication is that future competition will be won by ecosystems that balance small, private, always-available models with the selective reach of larger cloud systems. And what’s more is since the SLM will run local only, you as a user can feel a greater sense of privacy that your data isn’t going to some nexus API of the cloud company hosting the model.

Integration and Friction
What’s happening
The hardware race is accelerating as Meta’s Ray-Ban glasses, XREAL’s AR systems, and Alibaba’s Quark AI Glasses embed SLMs directly as native intelligence. Watches and XR devices are testing proactive agents driven by voice and gesture, though battery life and ergonomics remain unresolved bottlenecks. Efficiency-focused chip design is narrowing these gaps and making always-on intelligence more feasible.
So what
The strategic move is to prototype SLM-powered wearables now and secure ecosystem partnerships before the market hardens. Early dominance in niches like enterprise AR or health-focused XR could lock in user bases while incumbents are still fragmented. Businesses that delay risk entering too late, when hardware platforms and AI ecosystems are already consolidated.

Strategic Horizon
The roadmap based on the insights is straightforward.
Short term: Audit your current products, test SLM pilots in current tech stacks, and quantify agentic efficiency gains.
Medium term: Invest in proprietary training pipelines for SLMs and co-design with hardware vendors.
Long term: Scale ecosystems where SLMs operate seamlessly across phones, wearables, and glasses, capturing market growth that is projected to exceed $5.45B by 2032.
The Final So What
The rise of small language models is not just a technical curiosity, but a structural shift in how AI will be built, deployed, and monetized. By collapsing inference into devices that people already carry, SLMs flip the economics of AI from cloud-scale API cost centers, to edge-first ecosystems where latency, privacy, and efficiency are the real competitive moats.
This fundamentally creates two different markets. Those chasing the frontier with the largest models, and those that master co-design with hardware, distill data into specialized vertical agents, and orchestrate modular stacks where SLMs handle the bulk of queries while larger models serve as escalation paths.
Markets will reward companies that move early to integrate SLMs into wearables, AR systems, and everyday consumer hardware, capturing loyalty by making AI ambient, personal, and frictionless.
As the market expands, the decisive edge will belong to firms that see SLMs not as neutered LLMs, but as the foundation of a new computing paradigm where intelligence is directly embedded.
this is good
slm > llm indeed
Well, if SLM glasses can help people from walking straight into me while they are engrossed in their phone, then I can’t wait.