

Artificial intelligence has learned to see. Now it must learn to exist.
Fei-Fei Li, one of the most quietly influential figures in modern computing, has returned to the frontier with a new project.
Her aim is not just to build smarter systems. It is to give machines spatial intelligence the ability to understand, navigate, and interact with the three-dimensional world.
She is building the tools for a world where AI will not only label objects but will inhabit environments, simulate actions, and cooperate with humans in physical space.
The company she co-founded, World Labs, is developing a class of systems called World Models. These models don’t just recognize patterns. They build spatial representations. They infer geometry, track objects over time, and simulate causal interaction within environments. In short, they model the world around them, whether digital or material.
This is an attempt to solve a deep and unsolved puzzle in artificial intelligence. It’s also a continuation of the pattern that defines Fei-Fei’s career. She doesn’t chase hype. She builds the future. And every time, the field has reorganized around her.
Vision as Infrastructure
In 2012, a deep learning model called AlexNet cracked open a new era in artificial intelligence.
It was not the first neural network to process images. But it was the first to do it with scale, speed, and accuracy that could no longer be ignored. The model did not just win the ImageNet competition. It embarrassed everything that came before it.
AlexNet used convolutional layers to process visual data, ReLU activations to speed up learning, and dropout regularization to reduce overfitting.
These are now standard techniques. At the time, they were radical. The key was not just architecture. It was data.
AlexNet trained on a dataset called ImageNet a massive, meticulously labeled archive of images and object categories. ImageNet contained over 14 million images grouped into 20,000 categories. It wasn’t just large. It was clean, structured, and deep. The entire project was led by Fei-Fei Li, while she was an assistant professor at Princeton University.
The idea for the project began to take shape in 2006, (ten years before the Transformer Paper) inspired by Li's conviction that the future of artificial intelligence, especially computer vision, depended on large, high-quality datasets, not just better algorithms.
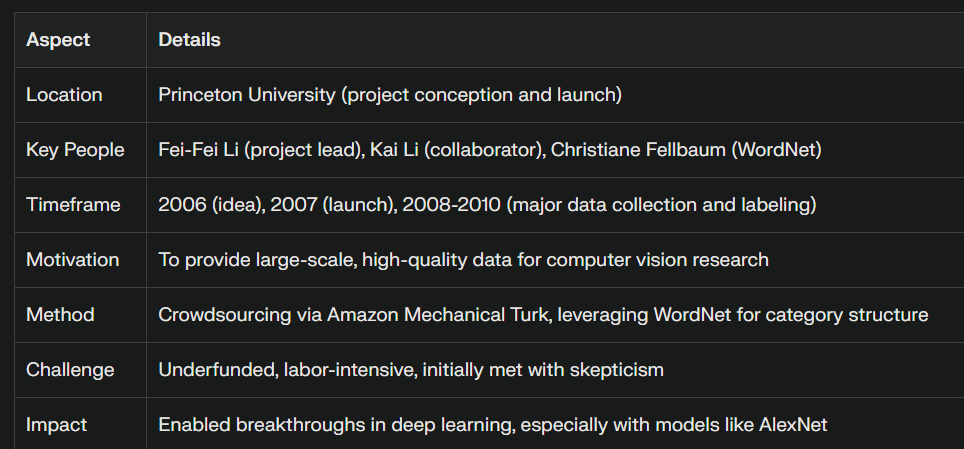
Li understood that vision systems don’t emerge from algorithms alone. They require a shared substrate. They require a common library of visual knowledge that models can be trained on, compared against, and improved over time.
ImageNet made computer vision reproducible. It created a benchmark that forced models to get better. It created a shared context that allowed research to accelerate. It did not chase novelty. It created the conditions for novelty to compound.
ImageNet was foundational in the purest sense. And in building it, Fei-Fei Li made modern computer vision possible.

From Labels to Worlds
Today, the “Godmother of AI” is building something much harder.
In 2024, she co-founded World Labs, a company developing a new class of models called World Models. These systems are designed to go beyond perception and attention mechanisms. They are designed to give machines an internal representation of physical space.
Most AI today operates in flattened domains. Language models process tokens. Vision models process pixel grids. Even video models typically treat time as just another axis of correlation.

These systems are powerful, but they are disembodied. They don’t form a coherent understanding of space. They can’t distinguish between being near something and being behind it.
They don’t know what it means for an object to be out of reach or partially occluded. They can’t move through an environment or simulate what would happen if they did.
This is a blind spot with massive implications. Robots can’t operate effectively in the real world without spatial intelligence.
Self-driving cars can recognize stop signs but can’t reason about intention.
Virtual assistants can’t plan actions in physical space.
Even generative models that produce 3D objects from text often rely on heuristics, not understanding.
World Labs is trying to close this gap.
Its models can transform 2D inputs into coherent 3D representations. They can simulate entire environments. They can take a sentence like “place the cup on the top shelf” and infer what kind of motion, grasp, and trajectory would be required. They can render and interact with worlds, not just surfaces.
This shift parallels biology. In evolution, sight preceded cognition.
Organisms had to perceive space before they could act in it. Perception created the substrate for action, planning, and intelligence.
Li believes AI must follow the same arc. Without spatial models, intelligence remains abstract. With them, it becomes embodied.
The Impact of Intelligence
If she succeeds, the ripple effects won’t be limited to the lab. Spatial intelligence will unlock capabilities that cut across industries. These are not future hypotheticals. They are direct consequences of machines gaining the ability to model and reason about space.

These are not niche applications. They are the foundation of human-computer interaction in the physical world. Without spatial intelligence, machines can describe. With it, they can act.
The Challenges Ahead
This level of intelligence does not come cheap. Spatial models require massive data, high-fidelity simulations, and large-scale compute. Training is slow. Generalization is hard. Inference is expensive. None of these constraints are trivial.
Li is aware of this. She is one of the leading advocates for national AI infrastructure. Through initiatives like the NAIRR Pilot, she is working to ensure that access to compute does not become a bottleneck that locks out progress.
Even so, investor confidence is already strong. World Labs emerged from stealth with $230 million in funding and a valuation north of $1 billion. When Fei-Fei Li builds something, the field realigns around it.
World Models

There is a difference between intelligence that predicts and intelligence that understands. Most current systems do the former.
They recognize patterns and return outputs. They do not build models of the world. They do not simulate cause and effect. They do not inhabit physical constraints.
Fei-Fei is trying to build systems that do. Her goal is not just better performance. It’s better grounding. Intelligence that knows where it is. Intelligence that understands what it can do.
We taught machines to recognize cars and cats. Then we taught them to answer questions and write code.
Now we are helping them reason by teaching them modus ponens and modus tollens.
The next step is to give them a body. Not necessarily a physical one, but a spatial one.
A mental map that lets them reason about motion, contact, structure, and geometry.
If she succeeds, we will not just interact with machines. We’ll be able to inhabit a space with them, be it digital or physical.
Like a child learning about its environment, AI should be thought of as a 2 year old being taught what objects are. They learn through constant interaction with their environment through all of their senses. Without vision, AI is losing one of the most important senses. Sound, taste, touch and smell are all necessary for something to be truly cognizant of its environment. I wonder which sense will be next?
This discussion of spatial intelligence in the context of AI conjures up questions of true understanding. These questions border on the philosophical.
AI is already proving to be a powerful tool to read, right, and generate images and video. But also display remarkably poor understanding, or perhaps no understanding, of what they are doing.
Something is missing, and I don’t know about the technology to speak as to what it is. Nonetheless, these tools are the future, and we should embrace them.
It is my sincere hope that AI leads us to accelerated economic growth in the near future. General human prosperity should be the goal.