


Peaking Inside the Mind of AI
Understanding how LLMs Think

"Our goal is to let people see the impact our interpretability work can have. The fact that we can find and alter these features within Claude makes us more confident that we’re beginning to understand how large language models really work.
This isn’t a matter of asking the model verbally to do some play-acting, or of adding a new “system prompt” that attaches extra text to every input, telling Claude to pretend it’s a bridge.
Nor is it traditional “fine-tuning,” where we use extra training data to create a new black box that tweaks the behavior of the old black box. This is a precise, surgical change to some of the most basic aspects of the model’s internal activations."
—Anthropic on their “Golden Gate Claude” experiment
Large Language models (LLMs) have become the pivotal force in artificial intelligence, enabling machines to perform tasks ranging from creative writing to medical diagnosis.
While perhaps not the architecture that will lead us to AGI, these models, exhibit human-like capabilities. Yet their internal processes remain opaque, often described as “black boxes.”
Understanding how AI “thinks” is not just an academic curiosity, but a necessity for ensuring safety, building trust, and improving these systems, especially as they integrate into critical sectors like healthcare, finance, and education.
What We’ve Learned So Far
Researchers are using tools like “circuit tracing” to map out how AI processes information, almost like drawing a wiring diagram of its “brain.”
This approach aims to create a “wiring diagram” of an AI’s internal mechanisms, identifying different components and their interactions. A key tool is the “attribution graph,” which traces the chain of internal steps an AI takes to arrive at an answer, helping researchers hypothesize and test underlying mechanisms.
Their studies on Claude, particularly Claude 3.5 Haiku and Claude 3.7 Sonnet, reveal several insights.
AI handles multiple languages and modalities through shared internal representations. These are abstract spaces where language, images, and audio all converge into vectors.
These vectors aren't human-readable, but they're deeply structured:
"king - man + woman" = "queen" only works because the model's internal space encodes these associations and relationships in a meaningful way.
What’s fascinating is that even when you input a prompt in Chinese natural language, the model might internally represent that meaning in a form closer to English, especially if its training data is disproportionately English.
This behavior reveals that AI “thinks” more fluently in some languages than others, even if it can technically handle all. These preferences are baked into its internal geometry, shaped by its weights and biases.

The weights in a neural network are just millions of numerical values that connect nodes. They “learn” relationships between inputs and outputs through training.
Biases, on the other hand help each neuron correct for systemic imbalances in input. Adjusting these two elements, tensions (weights) and alignments (biases), reshapes the entire model's output and perception.
Some weights, especially in middle transformer layers, affect how the model composes ideas, rather than what it says outright. If we can isolate these features, we can “turn up” the bias an LLM places on a specific weight.
Anthropic demonstrated this with their “Golden Gate Claude” model, when you 10x the emphasis on the weight “Golden Gate Bridge” by finding the corresponding feature.




This is why interpretability researchers sometimes visualize "circuits" in the model, like bridges of tension (no pun intended) running between concepts. These circuits can show you why a model thinks “Paris is in France” but not “Ottawa is in Canada,” even though both are factual.
One real-world implication of this is translation. If a model trained mostly on English is asked to translate Japanese to Arabic, it might route the ideas through English, first translating to English internally, then out to Arabic.
This isn’t an explicit rule but a pattern formed by weight configuration. So the path across the “bridge” isn’t direct, it detours through better-lit territory.
This detour creates subtle artifacts. Phrasing, idioms, or omissions that wouldn’t be there if the model had trained equally on all languages. We call this “nativity” in the biz.
Understanding the shape of the circuit, what the weights and biases encode, gives us clues to the AI’s internal “black box.”
We can’t always read its mind, but by observing how it bends toward some answers and away from others, we infer the load-bearing paths. This is known as Inner Conflict Feature mapping.
While this neighborhood does not cleanly separate out into clusters, we still find that different subregions are associated with different themes.
For instance, there is a subregion corresponding to balancing tradeoffs, which sits near a subregion corresponding to opposing principles and legal conflict.
These are relatively distant from a subregion focused more on emotional struggle, reluctance, and guilt between its system prompt of being helpful to a user, and its system prompt of giving harmless answers.

Research in probing and model editing is like testing the stress points on the Golden Gate bridge (I’m just running with this metaphor now). Where can we reroute traffic (ideas) without collapsing the span?
If we find that adjusting one node changes how the model writes love poetry, that node may be a kind of keystone. The goal is not to inspect every bolt, but to map the hidden architecture that lets the model span the gap from data to meaning.
When an AI writes poetry, it seems to plan rhyming words ahead, and for math, it might use one part for quick guesses and another for precise calculations. This suggests AI isn’t just memorizing answers but doing some form of thinking.
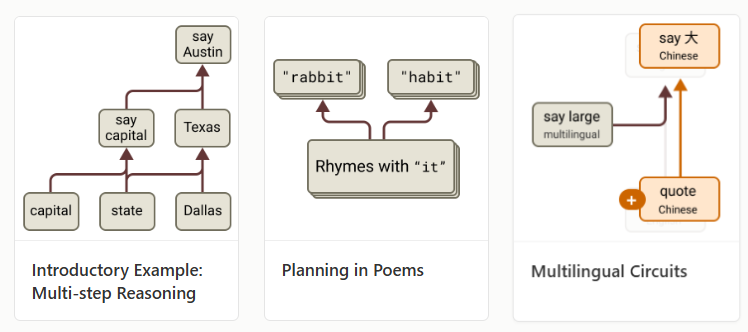
Multilingual and Multimodal Insights
AI also handles multiple languages and data types (like text, images, audio) in ways that seem universal. For instance, an English-focused AI might “think” in English even for Chinese text, then translate the answer. This helps explain why AI can switch languages, but it also shows some biases, like favoring English.
Challenges and Risks
LLMs, as probabilistic machines, can “hallucinate,” confidently giving wrong answers, especially if it mistakes unfamiliar things for known ones. Also, when AI explains its reasoning (called “chain-of-thought”), it sometimes makes up steps that don’t match how it actually worked, which is worrying for safety, especially in critical areas like healthcare.
Where We’re Headed
It’s early days, and much is still unclear, like how these findings apply to all situations or handle complex tasks.
But for me, this remains the most bleeding edge and interesting area of technological development. Building intelligence and scaling it to the world in a safe and effective way.
For more details, check out Anthropic Research or MIT News.
Amazing work. So exciting!!!
It is interesting that the models favor English. They will all need be to be trained in all the “common” languages to avoid translation confusion. One would hope the medical AI’s are being trained in Latin. Even though this is an “ancient” language.